Insight Catalog

データカタログ機能をベースに
ビジネスメタデータ管理や名寄せ機能を搭載し、
データの可視化を実現
ビジネスメタデータ管理や名寄せ機能を搭載し、
データの可視化を実現
データの特徴や属性を自動的に解析して、データのビジネスにおける意味合い、隠れた属性や結びつきを可視化。日本語にも対応した自然言語処理AIを搭載し、直観的なUIにより企業の迅速な意思決定を支援する。
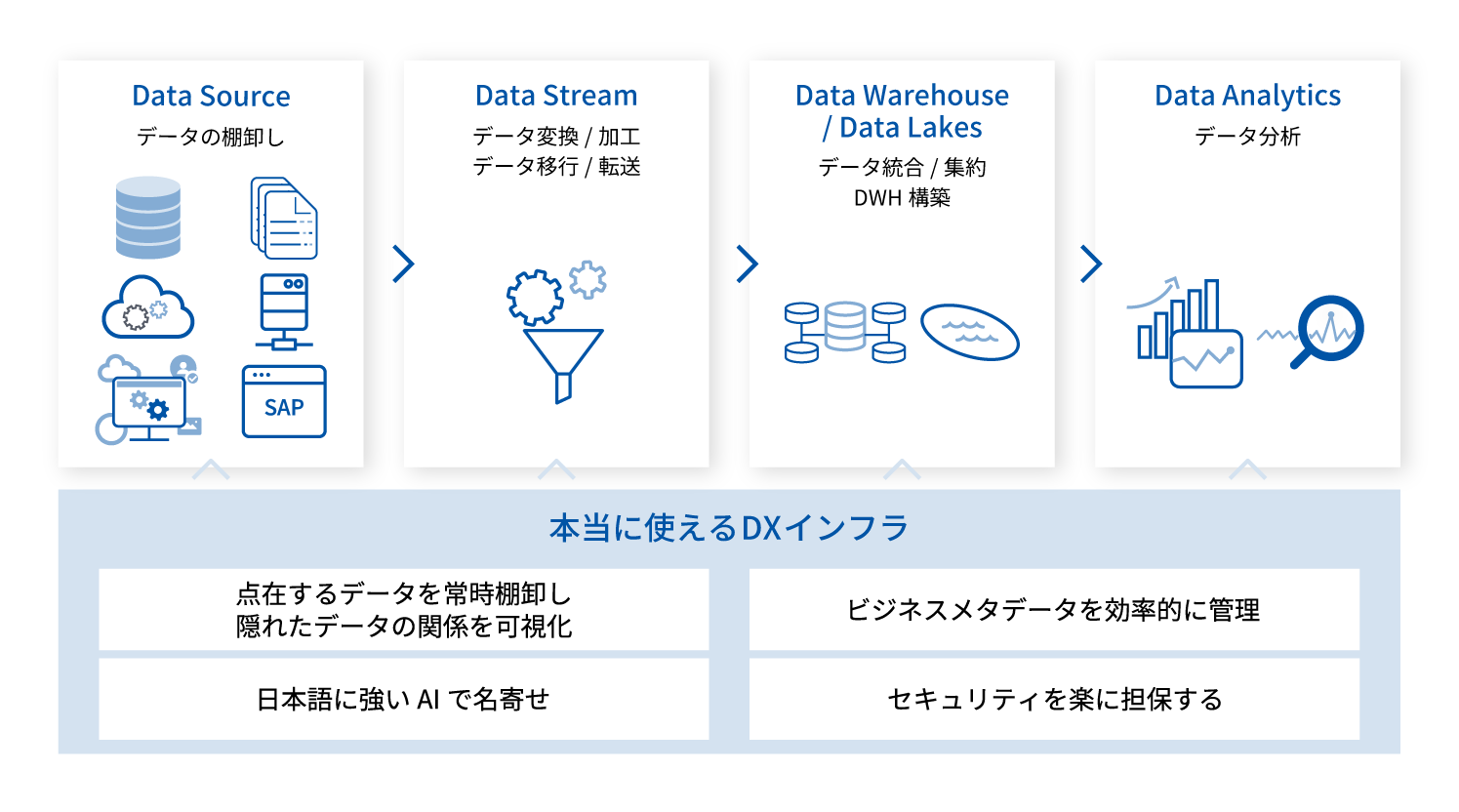
企業に眠っている大量のデータから、いつでも誰でも安全にデータを利用できる
「データ活用基盤」の構築を実現する。
「データ活用基盤」の構築を実現する。
Insight Catalogの特徴
01 データ活用における課題を解決する機能
「データの棚卸しをしようとしても、日々データが増え続けるために内容の把握が難しい」「日本語テキストの名寄せはどうしても手作業になる。乱立するデータウェアハウス(DWH)を日本語のメタデータで管理できる製品がない」「手っ取り早くBIを導入するにも、個人情報などのセンシティブな情報に社員をアクセスさせられない」……
Insight Catalogは、こうしたデータ活用における課題をセキュリティ要件を満たしながら解決します。
02 データ可視化
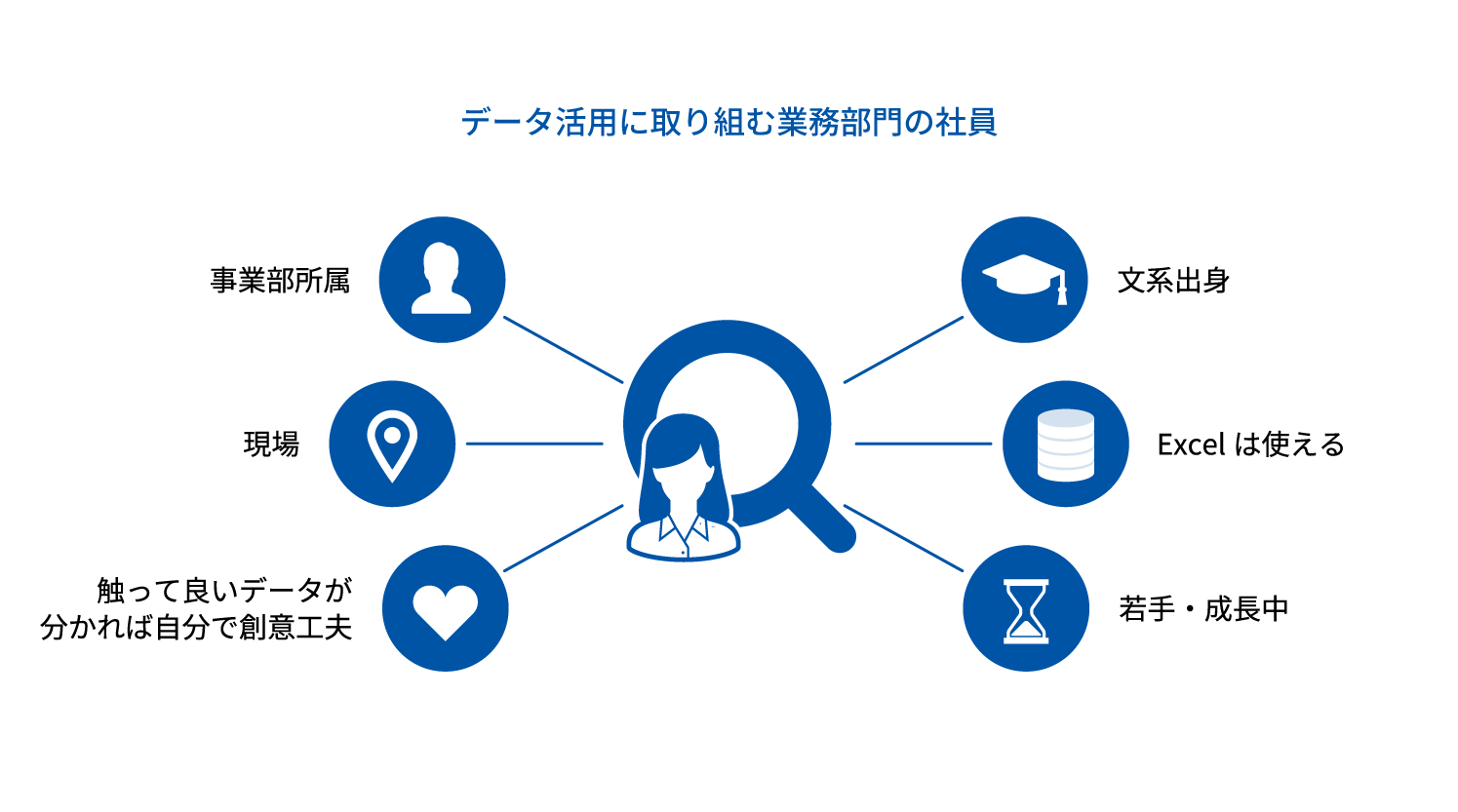
データの一元管理の仕組みがない企業では、社内の各部門がそれぞれに持っているデータソースを管理しきれていないことがほとんどです。データを有効活用するためにはそれらのデータを可視化し、棚卸しする必要があります。Insight Catalogなら、各部門に散在しているデータを簡単なクリック操作で可視化できるため、一般社員でもデータを有効活用可能な状態にすることができます。
03 セキュリティ自動組み込み
データを見える化して活用する際、適切にアクセスを制御することによって個人情報などのセンシティブな情報を守る必要があります。Insight Catalogはセンシティブなデータへのアクセス権やデータの複製権限をユーザーの役割や所属に応じて制御でき、すべてのデータ操作の履歴を記録や検索することができます。
04 ビジネス価値生成
すでにデータウェアハウス(DWH)などへデータソースを統合していても、膨大なデータから意味を見出すためのビジネスメタデータがなければ有効活用は困難です。Insight CatalogならAIにより各種メタデータを自動的に付与できるため、データのビジネスにおける意味合いや隠れた結びつきをもとに、簡単に目的のデータを探すことができます。また、今後はお客様独自のビジネスドメイン知識を学習したメタデータを自動付与する機能も検討しています。
05 日本語AI搭載
膨大なデータの見える化を進めるにあたり、データの中身や属性を人がチェックして判断するのには限界があります。日本語を適切に理解するAIにより、メタデータ付与の自動化・半自動化や異なるデータソースをまたいで関連データを自動検出する機能を搭載し、Insight Catalogがお客様の作業効率化、工数の削減にお役立ていただけます。
Insight Catalogの機能
FUNCTION 01 データカタログ
マルチデータベース、マルチデータストア(csv形式やフリーテキスト形式など非構造化データ含む)のデータをすべてカタログとして一覧化・可視化。クリック操作で簡単にデータソースの登録ができ、かつ短期間で導入可能なデータディクショナリ機能を備えます。それにより、登録されたオブジェクトやカラム・メタデータに対し、検索等のブラウジング機能を提供します。
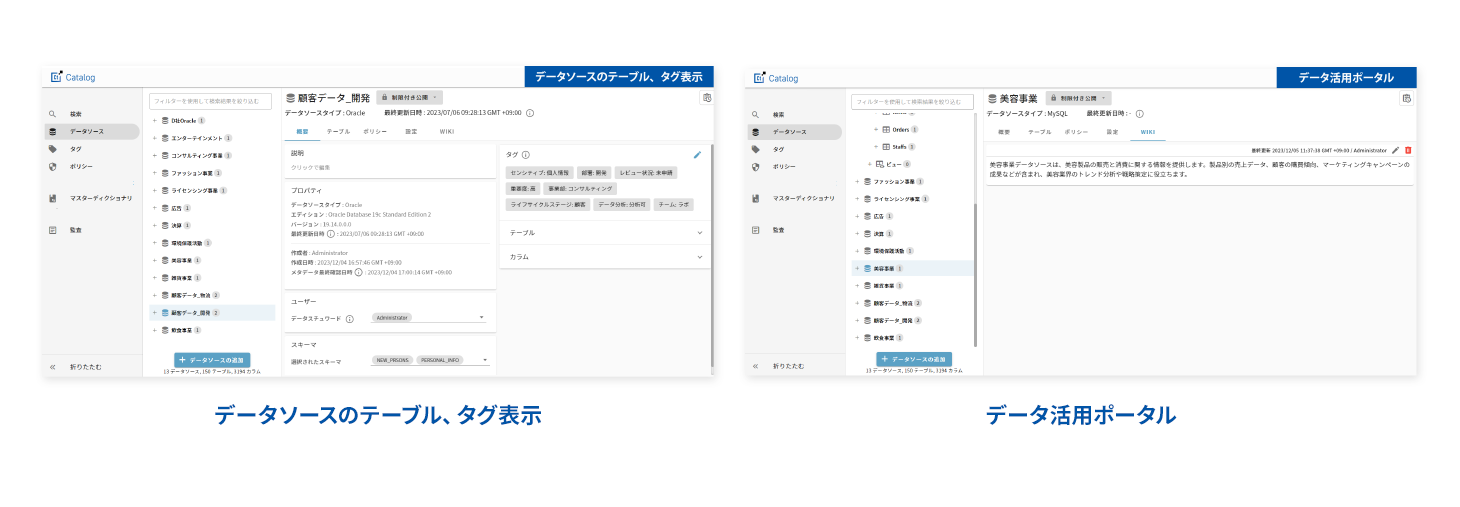
FUNCTION 02 ビジネスメタデータ管理
カラムごとのデータをAI解析して、氏名・電話番号・住所などのメタデータを自動付与。各種データにタグを付与することで、タグでカタログ内を横断的に検索可能にします。
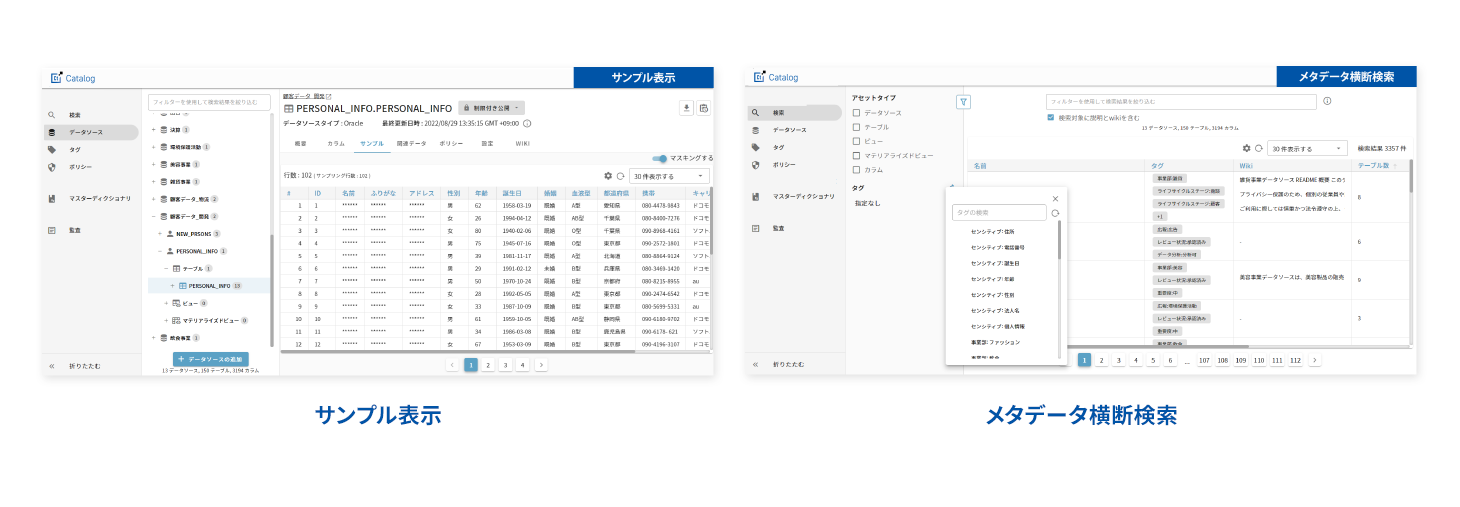
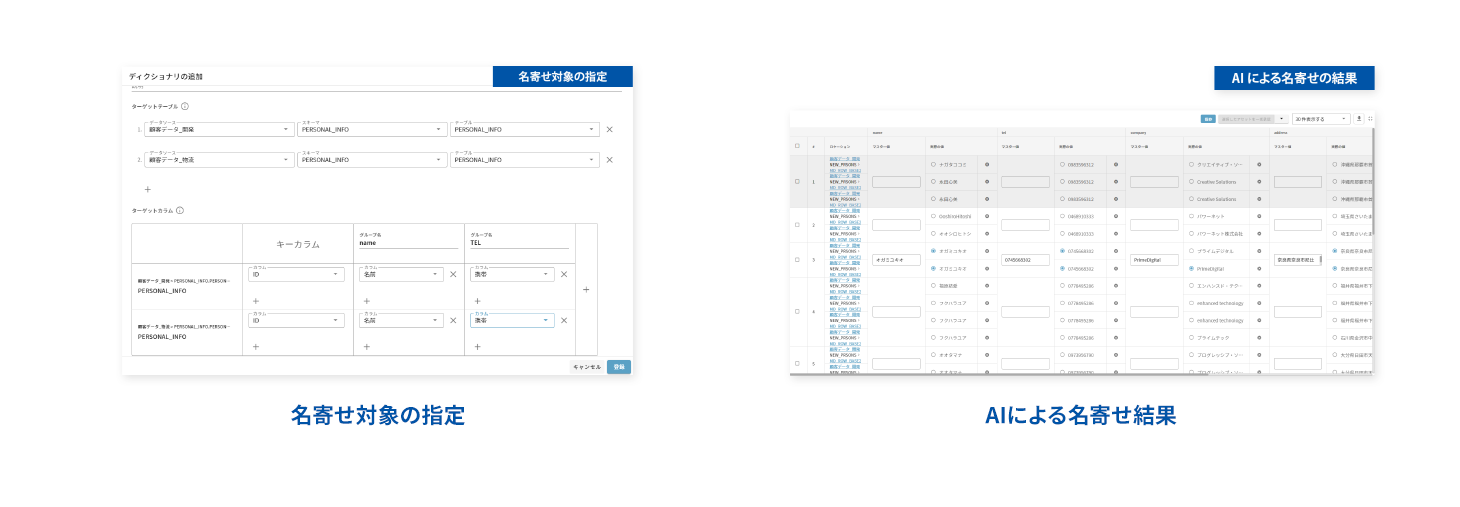
FUNCTION 03 マスターデータ管理
対象のテーブル・カラムに対し、日本語に強いAIが自動的に高精度な表記ゆれの分析を行い、名寄せ候補を推奨します。膨大なデータを突き合わせることなく、候補を選択するだけで名寄せを行うことができます。
これにより、顧客情報を登録する際、顧客名の表記ゆれを防ぐことができます。また、異なるシステム間でのデータ連携時に名寄せの変換ルールを適用することで、データ整備工数を大幅削減し、正しいデータの即時活用が可能となります。
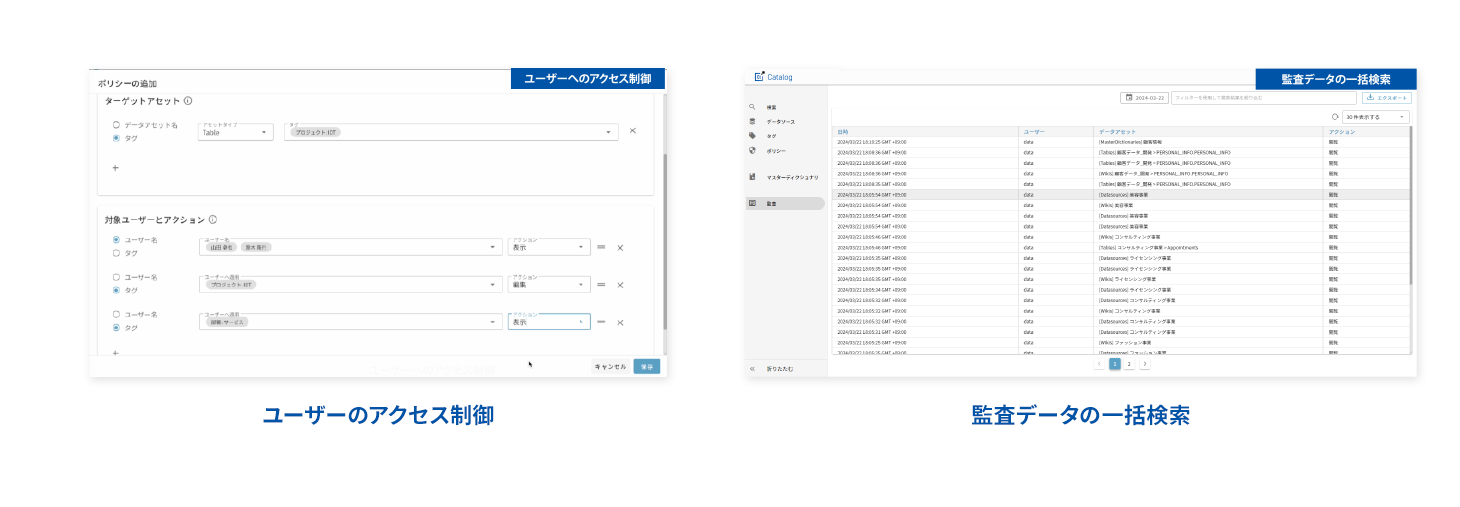
FUNCTION 04 アクセス制御・監査
タグによる属性ベースでのアクセス制御、カタログ上での表示/非表示の制御機能で、データソースやデータウェアハウス(DWH)へのアクセスログを一元管理。個人情報を含むデータへのアクセスを一括検索でき、閾値での警告、特権ユーザー管理等の機能を提供しています。
Insight Catalogの
対応環境
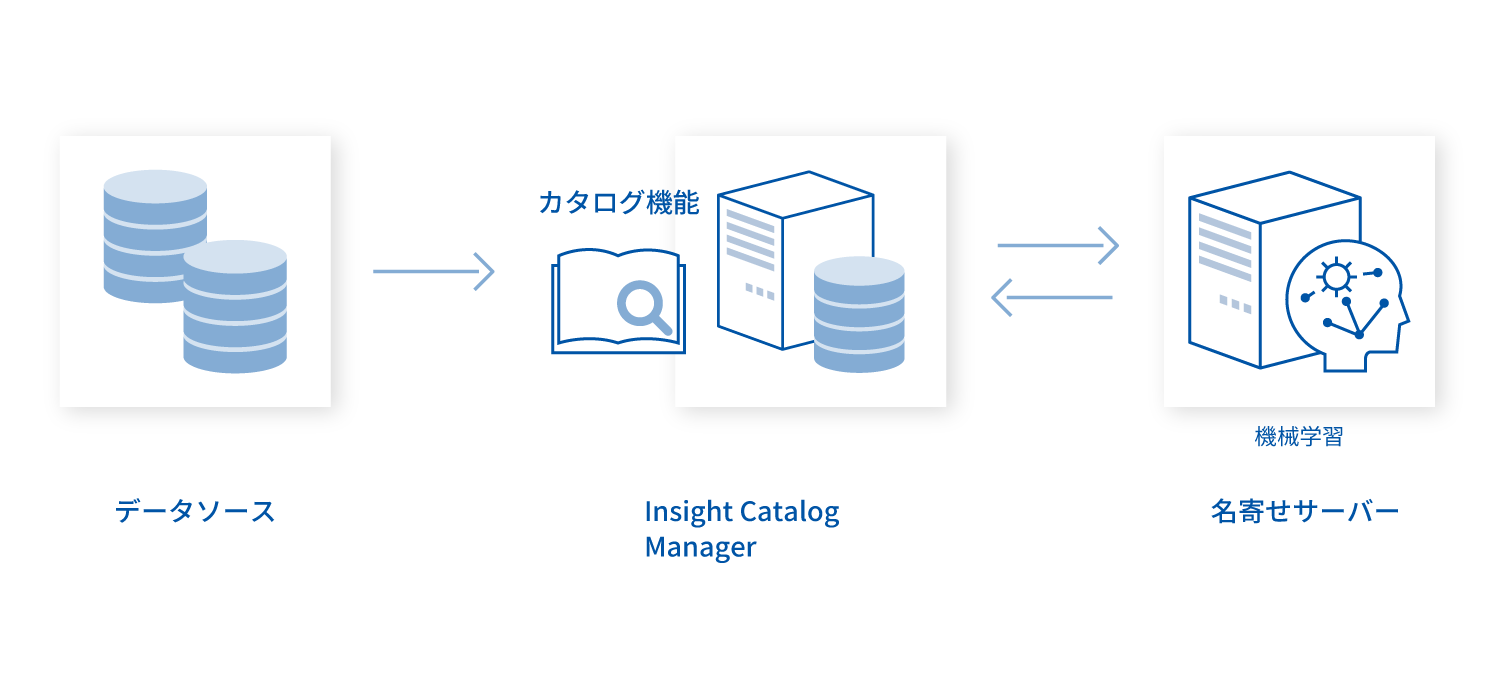
システム構成
稼働環境
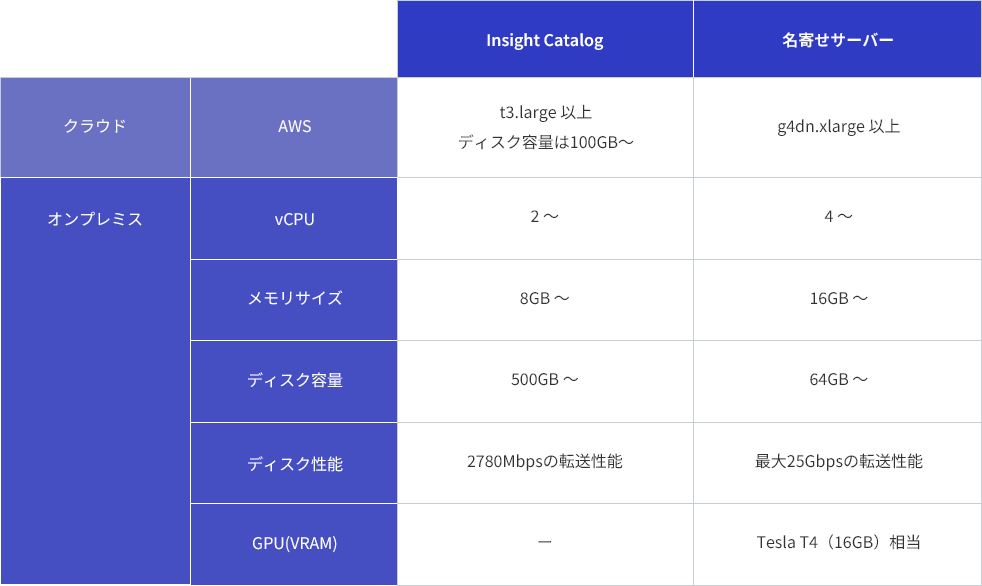
- Insight Catalogは、仮想アプライアンスでの提供となります。
- Vmware ESXiのVM形式(オンプレミス環境向け)
- AWSのAMI形式(クラウド環境向け)
- MDM(名寄せ)を行う場合、別途ESXi上のGPUサーバーまたはAWSのGPUインスタンスが必要となります。
(名寄せの性能目安は、対象行数が1000行で約30分ほどかかります。)
| 対象データソース |
Oracle Database/Microsoft SQL Server/PostgreSQL/MySQL/MariaDB/Snowflake/ Amazon Redshift/Teradata/Amazon RDS for Oracle/Amazon RDS for SQL Server/ Amazon RDS for PostgreSQL/ Amazon RDS for MySQL/ Amazon Aurora(PostgreSQL/MySQL互換エディション)/ Apache Hive/Trino/ Presto |
|---|
※今後、対応データソースを拡大予定
Insight Catalogが解決する課題
01 情報システム部門やデータサイエンティストに依頼していたデータ収集・加工が現場で可能に。経営判断を加速させる
データ分析に必要なデータを収集し意味がわかるものに加工するために、情報システム部門や外部委託のデータサイエンティストに依頼する必要がなくなります。経営会議に必要な資料の作成が効率化されるのはもちろん、経営者もデータをすぐ見ることができるようになります。また管理部門は面倒な管理業務から解き放たれ、別の業務にリソースを割くことが可能になります。
02 分散しているデータベースを横断して膨大なデータをカタログ化。可視化されたデータをリアルタイムに利用可能にする
マルチデータベースに対応し、横断して検索を行って意図した用途に適したデータを見つけ活用するためのデータカタログ管理を実現。データボリュームの肥大化にも長期にわたって対応可能です。
03 データ保護の法令遵守に対応する
データを保護するためのインシデント管理・コンプライアンス管理・リスク管理・監査管理の仕組みが充実。個人情報を自動で匿名化する機能により、社内の業務部門や外部委託業者は匿名加工情報を利用できるようになりパーソナルデータの安全な活用が促進できます。
Insight Catalogの
利用シーン
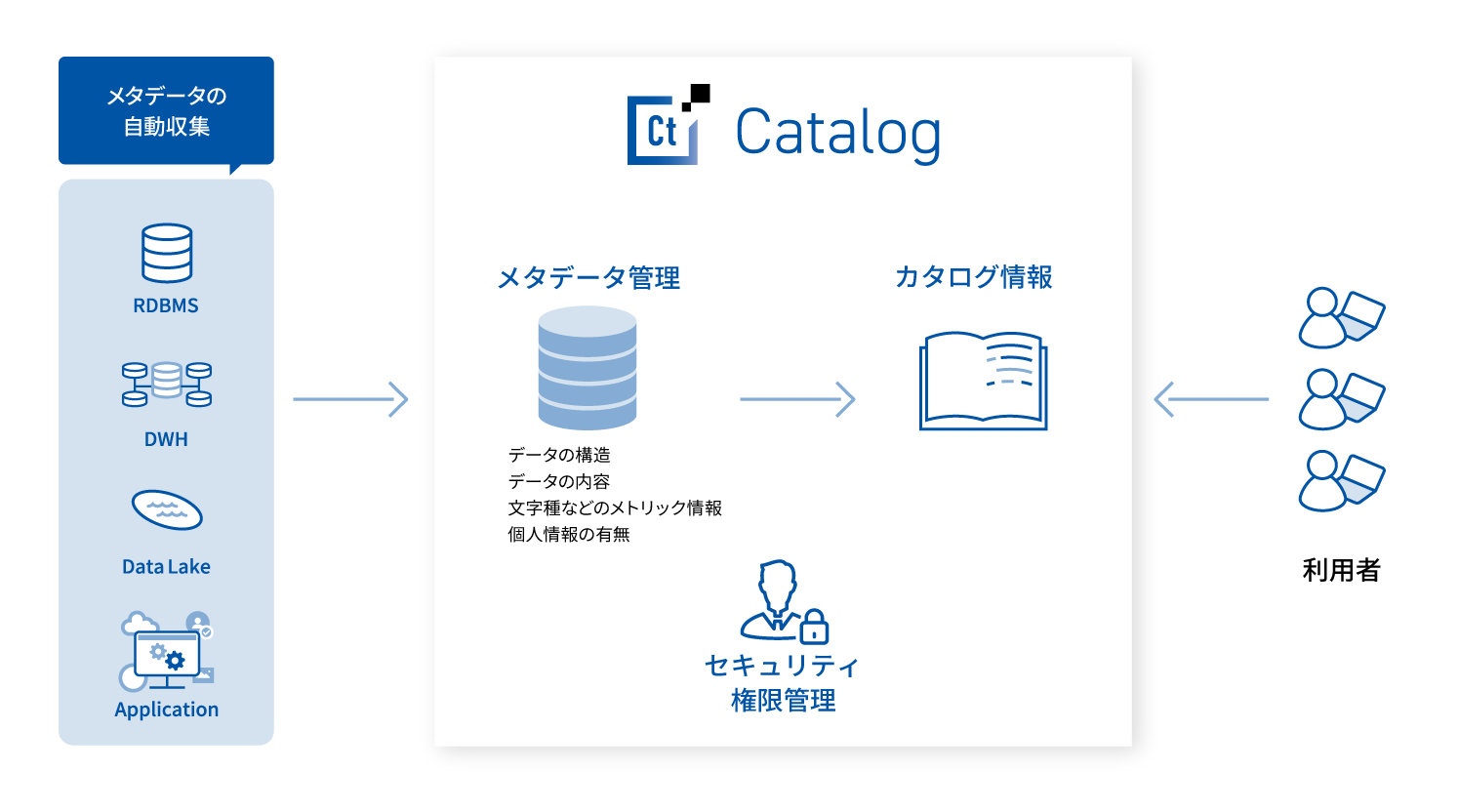
データの利活用 (データソース登録、メタデータ管理、カタログ化、セキュリティ管理)
- 分断、分散するデータを可視化し、データ利活用を推進
- 会社のデータ基盤上にあるメタデータをデータカタログ化。データ検索の仕組みを構築
- 会社全体のデータカタログを自動的に構築し、ユーザーが業務に使用。データを検索・抽出できる環境を構築
- 異なるデータソース間で、AIによって関連データを検知・紐付け、可視化されていないコピーデータ(二重データ)を検出

データの表記ゆれの検出、名寄せ
- 手作業で行っている名寄せをAIで名寄せをし、効率化
- 正確な分析や顧客データの高品質化