こんにちは、インサイトテクノロジー 札幌R&Dセンターの吉﨑です。
PostgreSQLへのInsertを速くしたくなったけど
- 定番のCOPYのために処理を書き換えたくない
- BULKのために文字列連結でSQL文作り出したくない
そんなときにDBサーバーはそのままでクライアントライブラリだけで速くできる救世主のような機能がバージョン14でやってきたので試してみました。
パイプライン機能
PostgreSQL14のクライアントライブラリで可能になったクエリの送信方法
非同期クエリは以前から存在していましたがあくまでサーバーの処理結果を待つ間クライアントプログラムが自由になるもので1つ1つ処理をリクエストする必要がありました。
パイプラインモードではクライアントサイドでリクエストをバッファリングしてまとめてサーバーに送ることでネットワークレイヤーのオーバーヘッドを減らせます。
書き方
基本の流れ
- パイプラインモードに入る
- クエリ発行(バッファリング)
- フラッシュ・結果要求
- 結果読み取り(バッファリング)
- パイプラインモードを抜ける
※※※ 解放処理を省略しているのでそのまま使わないこと
#include <libpq-fe.h>
PGconn* cn = /* 接続 */
PGresult* res = NULL;
int ret;
int i;
// 非同期モードへ入る
ret = PQsetnonblocking(cn, 1);
if (ret != 0) { /* error */ }
// パイプラインモードへ入る
ret = PQenterPipelineMode(cn);
if (ret != 1) { /* error */ }
// クエリ例
// 関数呼び出し後の ret != 1 のチェックは省略
// (1) 暗黙のトランザクション
// 次のPQpipelineSyncを呼び出すまでがトランザクションの範囲
ret = PQSendQuery("INSERT INTO t (col1) values (val1)");
ret = PQSendQuery("INSERT INTO t (col1) values (val2)");
ret = PQSendQuery("INSERT INTO t (col1) values (val3)");
ret = PQpipelineSync(cn);
// クエリ発行分の結果を消費
// コマンド結果取得の後はNULLを受け取り次の結果取得に移る
for (i=0; i<3; i++) {
res = PQgetResult(cn);
if (PQresultStatus(res) != PGRES_COMMAND_OK) { /* error */ }
assert(PQgetResult(cn) == NULL);
}
// sync結果受け取り
res = PQgetResult(cn);
if (PQresultStatus(res) != PGRES_PIPELINE_SYNC) { /* error */ }
assert(PQgetResult(cn) == NULL);
// (2) 明示的なトランザクション
// PQpipelineSyncをまたいで可能
ret = PQSendQuery("BEGIN");
ret = PQSendQuery("INSERT INTO t (col1) values (val2)");
ret = PQpipelineSync(cn);
ret = PQSendQuery("COMMIT");
ret = PQpipelineSync(cn);
/* 結果消費処理 略 */
// (3) データ取得
ret = PQSendQuery("SELECT 10;");
ret = PQpipelineSync(cn);
res = PQgetResult(cn);
if (PQresultStatus(res) != PGRES_TUPLES_OK) { /* error */ }
PQgetvalue(res, 0, 0); // => "10"
assert(PQgetResult(cn) == NULL);
res = PQgetResult(cn);
if (PQresultStatus(res) != PGRES_PIPELINE_SYNC) { /* error */ }
assert(PQgetResult(cn) == NULL);
// (4) PQpipelineSyncを使用しないバッファ送信
// クライアントの使用メモリ量や帯域調整のためにバッファの送信をする場合
// PQflushが1を返す場合は送信しきれていないので待つ必要がある。
ret = PQSendQuery("xxx);
ret = PQflush(cn); // キューイングされているデータを送る
/* 省略 */
// (5) PQpipelineSyncを使用しない結果要求
// サーバーで処理済みの結果を要求する
ret = PQSendQuery("xxx);
ret = PQsendFlushRequest(cn); // サーバーの持つバッファの吐き出し要求
ret = PQflush(cn); // PQsendFlushRequest自体もキューイングされているので送る
/* 省略 */
// パイプラインモードを抜ける
ret = PQexitPipelineMode(cn);
if (ret != 1) { /* error */ }
// 非同期モードを抜ける
ret = PQsetnonblocking(cn, 0) != 0);
if (ret != 0) { /* error */ }
PQclear(res); // !!! 本当はここ以外でもPGresult*は都度解放すること
PQfinish(cn);
既存の非同期処理関数で成功を示すのは0なのに対してパイプライン処理関数は1が正常を示すのが趣深いですね。
PQsetnonblockingを忘れて非同期モードに入らなくてもパイプラインの関数は呼び出せてしまいますが予期せぬデッドロックを引き起こすので気を付けましょう。
クエリの結果は呼び出した順に全て消費しないとパイプラインを抜けるときにエラーとなります。
PQSendQueryなどの送信データはバッファリングされつつ随時送信されます。
ネットワークが間に合わない場合はバッファの全ての送信を待たずに次の命令を受け付けます。バッファの縮小はされないのでクエリや環境によっては適宜PQpipelineSyncの呼び出すか、PQflushが0を返すまで呼び出してバッファー量を調整する必要があります。
処理結果はサーバーにバッファーされ、PQPipelineSyncやPQsendFlushRequestでクライアントに吐き出されます。こちらも適当なタイミングでPQgetResultとPQclearで読んで解放しないとメモリが埋まります。
計測
まとめて送るならきっと速くなると信じて計測してみましょう。
計測プログラム https://github.com/insight-technology/libpq14-benchmark
単純なブログ記事を保存するテーブルを想定してテキストを2カラム挿入します。
100万件INSERTしたテーブルサイズは1.3GBです。
トランザクションは最初にBEGIN、最後にCOMMIT相当の処理をします。
パイプラインは最後にPQpipelineSyncをします。
比較対象
- プリペアド文の同期呼び出し
- プリペアド文のパイプライン呼び出し
- 値埋め込みSQLのvaluesを連結したBULKインサート(1万件ごとにまとめる)
- COPYコマンド
シンプルな同期処理とinsertを速くするときの定番のbulkとCOPYとで比較します。
BULKでない値埋め込みSQLは遅すぎたので計測プログラムにはありますがここでは除外します。
データ
テーブル
CREATE TABLE insert_performance_test (
id SERIAL PRIMARY KEY,
title VARCHAR(100),
content TEXT,
created_at timestamp DEFAULT CURRENT_TIMESTAMP
);クエリ
-- プリペアド文
INSERT INTO insert_performance_test (title, content) values($1, $2);
-- 値埋め込みSQLのBULK
INSERT INTO insert_performance_test (title, content) values('hoge', 'fuga'), ('hoge2', 'fuga2') ,,, ('hogeN', 'fugaN');
-- COPY
COPY insert_performance_test (title, content) FROM STDIN WITH CSV DELIMITER ',' QUOTE '\"';環境
EC2からRDSにクエリを投げます。
EC2
OSはUbuntu20でストレージ・CPUがボトルネックにならない環境を設定
spec: (describe-instances抜粋)
{
"InstanceType": "/* c4.largeとc5.largeを切り替えて確認 */",
"Placement": {
"AvailabilityZone": "ap-northeast-1d",
},
"Architecture": "x86_64",
"EbsOptimized": true,
"Hypervisor": "xen",
"RootDeviceName": "/dev/sda1",
"RootDeviceType": "ebs",
"VirtualizationType": "hvm",
"CpuOptions": {
"CoreCount": 1,
"ThreadsPerCore": 2
},
}RDS
パイプライン機能は13以前のサーバーでも使用できるので確認のために11を使います。テスト時に作成したEC2のAvailabilityZoneがap-notheast1dだったのでRDSも同じ場所に置きます。
spec: (describe-db-instances抜粋)
{
"DBInstanceClass": "db.m5.large",
"Engine": "postgres",
"AllocatedStorage": 100,
"DBParameterGroups": [
{
"DBParameterGroupName": "default.postgres11",
"ParameterApplyStatus": "in-sync"
}
],
"AvailabilityZone": "ap-northeast-1d",
"EngineVersion": "11.13",
"Iops": 3000,
"OptionGroupMemberships": [
{
"OptionGroupName": "default:postgres-11",
"Status": "in-sync"
}
],
"StorageType": "io1",
"StorageEncrypted": true,
}結果
ある1回実行の計測時間
処理中の通信量を https://github.com/netdata/netdata で見ています。
EC2インスタンスタイプ c5.large
| 処理時間(秒) | 備考 | |
| 同期・プリペアド文 | 282 | |
| パイプライン・プリペアド文 | 23 | メモリ使用量大 |
| バルク | 24 | |
| COPY | 25 |
トラフィック

山は左から順に同期、パイプライン、バルク、COPYです。下側の赤い領域が送信量です。
c5.largeのEC2からでは同期以外で同等の速さが出ました。
これはパイプライン機能を使ったときの計測プログラムの出力です。
pipelineprepared start
start insert query 0 ms
finish insert query 10601 ms
marks a synchronization point 0 ms
finish consuming results 12106 ms
pipelineprepared finish 22708ms全体約23秒のうち10秒で100万件のPQsendPreparedの関数呼び出しを終えます。PQpipelineSyncの呼び出し前からクエリを送信し続けますが、今回は100万件までsyncしなかったのでメモリ使用量は送信が間に合わず肥大化したバッファの影響で大きくなりました。
EC2インスタンスタイプ c4.large
| 処理時間(秒) | |
| 同期・プリペアド文 | 331 |
| パイプライン・プリペアド文 | 50 |
| バルク | 32 |
| COPY | 46 |
トラフィック

山は左から順に同期、パイプライン、バルク、COPYです。下側の赤い領域が送信量です。
次はc4.largeインスタンスで実行しました。
c5インスタンスと比較して出ず、パイプラインとCOPYの方がバルクより遅くなっています。
インスタンスタイプによる違い
Wiresharkでパケットを観察するとエラーがパイプラインとCOPYのときに一定量出ていました。
c4.largeでのパケット量(黒線/RDSへのIPアドレスでフィルタ)とエラーパケット量(赤棒/フィルタは設定できず)
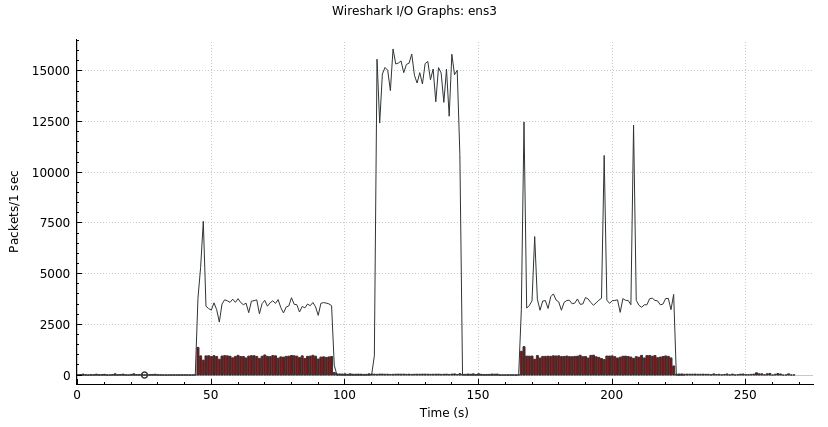
エラーは帯域制御の TCP Zero window と TCP Window Full です。
同期のクエリは行儀よく送受信を行いますがパイプラインとCOPYはとにかくデータを送ろうとして細かい帯域制御のパケットが飛び交っています。遅いときに、インスタンスサイズに応じて設定されるネットワーク帯域やパケット毎秒(pps)制限で天井に張りついてはなさそうです。拡張ネットワークのインターフェースの差がありそうですが今回は検証していません。
流量が似ていたりスパイクがあったり調査は面白そうですのでベンチマークをしてみたいですね。
ネットワークまわりメモ
| インスタンスタイプ | ネットワーク帯域 | 拡張ネットワーキング |
| c5.large | 10Gbps | Intel 82599 VF |
| c4.large | 中 | Elastic Network Adapter |
まとめ
とにかく速さを求めてインサートのみならばCOPYを使った方がよいです。
インサート以外のクエリが必要だったり既存のクエリに手を入れたくない場合にパイプライン機能が便利です。
同期
- pros
- シンプルでコードが単純
- cons
- 遅い
パイプライン
- pros
- 同期処理に対してメソッドを変えるだけで比較的書き換えやすい
- cons
- サーバー・クライアント双方のバッファー量に注意して適宜フラッシュ操作の必要がある
バルク
- pros
- 単純にリクエスト回数を減らしやすい
- cons
- 値埋め込みの結合は危険
- C-APIでプリペアド文を使うならば
insert into t values ($1,$2), ($3, $4)...($x, $x+1)とする - 鋼の意思で自前で書くか信頼できるライブラリに任せられるならあり
COPY
- pros
- リソースに対する負荷が低く安定して速い
- cons
- 1つのテーブルへの決まったデータの挿入のみ
- select, upcert (on conflict)する場合は使えない
- COPY用にデータを整形する必要がある
- PostgreSQL13以前で進捗がわからない
- 14から便利なビューが用意されました。pg_stat_progress_copy
未検証
以下は今回検証できていません。
- サーバーのリソースに余裕がない場合
- COPYの方がCPU効率がよさそうです
- COPYのバイナリモード
- 非同期のCOPY
- c4.largeでの実行時のボトルネック


