こんにちは。インサイトテクノロジーの松尾です!
このブログを書いているのはもう6月。札幌では先日北海道神宮祭が久しぶりに開催され、私の家族も行ったのですが、それはそれは大変な混雑だったようです♪
文章の中の個人情報を隠したい
メールの文章やチャットのやり取り、アンケートの自由記入など、世の中には定型化されていないテキスト(文章)データがたくさん存在しています。
そのような文章を利用したり公開する際に問題となるのが個人情報などの存在です。
個人情報等の機微なデータが含まれている場合には、情報漏洩の危険性もあることから、社内の分析用途であったとしても、利用に制限がかけられることが一般的です。
公文書の開示における黒塗りも、不都合な情報隠したいからではなく、個人情報保護の観点から、個人を識別できる情報を隠しているためです。
墨消し作業には相当なコストが・・・かかっているはず
墨消しはどのように行っているのでしょうか?
PDFなどのファイルに対して “墨消しツール”(または “黒塗りツール”) なるもので作業するのが一般的です。Googleなどで検索するとたくさんヒットしますね。
それらのツールは、人が指定した箇所を黒塗りしてくれるツールであることがわかります。
すなわち、文書の中から個人情報を探すのは「人力で」行われなければなりません。
人には間違いもあります。ダブルチェック、トリプルチェックを経ても100%に近づくとは思いますが、100%にはなりません。でも個人情報が漏れたら一大事。おそらく多大なコストをかけて墨消し(黒塗り)作業を行っているであろうことは想像に難くありません。
マスキング作業に追われて、本来の業務を行う時間が圧迫されている、ということもあることと思います。
また、ツールの使い方の問題で情報が漏れてしまう、なんてことも頻繁に起きているのです・・・。
文章内の個人情報を自動判別して黒塗り作業を超省力化
そんなコストをかけて実施している手作業を大幅に簡略化。
Insight Data Maskingは文章内の個人情報を自動判別することができるため、個人情報を含む文章から、効率的に個人情報の除去を行うことができ、
本来行うべき業務にかける時間を取り戻すことができるのです。
Insight Data Maskingによるマスキング処理は以下の流れで行います。
- 対象データの登録
- マスキングの実行前の確認
- マスキングの実行
- マスキング結果の取得
上記は、一般的なCSVファイルとして格納されている文章対するマスキング手順です。
なお、Insight Data Maskingでは、OracleやSQL Serverといったデータベース内のデータもマスキング可能です。
ではさっそく、Insight Data Maskingを使って文章をマスキングしてみます。
今回マスキングした元データ
このブログでは元データとして以下のCSVファイルを対象とします。個人情報が入りまくってますね!(弊社のブログ、事例、Wikipediaの記事です)
Name,Contents
松尾拓真(https://www.insight-tec.com/tech-blog/idt/20211223_idt_oracle/),"こんにちは。インサイトテクノロジーの松尾です!
札幌は今年の初雪がだいぶ遅かったですが、この冬は降りますかねぇ?
さて、とうとう Oracle Database 12c の EOL ( end-of-life、サポート終了 ) が来年 ( 2022年 ) に迫ってきました。それに伴って、RDS などのマネージドデータベースも EOL 予定を発表していますね!
参考:現在のデータベース・リリースのリリース・スケジュール (Doc ID 2413744.1)
参考:Amazon RDS for Oracle バージョン 12.1.0.2と12.2.0.1 のサポート終了のお知らせ
Oracle Database をサポート付きできちんと使い続けるにはデータベースバージョンのアップグレード ( バージョンアップ ) が必要となりますが、Oracle も AWS も、データベースバージョンのアップグレードにあたってのアプリケーション動作のテストを強く推奨しています。
ということで、一般的な Oracle Database を利用されている方々はこの EOL のタイミングの前に、アプリケーションのテストをして Database バージョンのアップグレードを実施していくことと思います。"
Paypay銀行事例(https://www.insight-tec.com/resource/qlik-replicate/paypaybank/),"事例概要 – PayPay銀行株式会社
PayPay銀行では既存の情報系データベースの処理性能不足問題を解決するため、クラウド上に分析データベースを構築し負荷を分散することを考えた。新たな分析データベースのために選んだのが、Amazon RedshiftとデータインテグレーションツールのQlik Replicateだった。
さらにデータマスキングツールのInsight Data Maskingも併せて採用される。これらを組み合わせた分析データベースでは、データ同期が自動化され、個人情報のデータをマスキングしても柔軟な分析が迅速に行える環境が完成した。
導入背景 – 性能劣化の課題解決のためクラウド上に新たな分析データベースの構築を検討
2000年10月に日本初のインターネット専業銀行として誕生したジャパンネット銀行。2021年4月にはPayPay銀行に改称され、Zホールディングスの各サービスとの連携を強化している。
PayPay銀行の口座数は約550万、預金残高はおよそ1.3兆円、ピーク時には1時間当たり67万あまりの取り引きが行われ、ユーザーの3割がPC、7割がスマートフォンでサービスを利用している。Yahoo!はもちろん、freeeやMoney Forward、JRAやBOATRACEなど多くの提携先があり、PayPayやLINE Pay、メルペイなどさまざまなスマホ決済とも連携している。また顧客サポートではLINEを使ったAIチャットなども実現し、さまざまな面から顧客満足度向上に取り組んでいる。
多くのサービスと連携しより良いサービスを提供するには、データ活用が欠かせない。そのため「社内においては、データ活用のためのデータ分析基盤が極めて重要となっています」と言うのは、PayPay銀行株式会社 IT本部 開発二部 基盤開発第一グループ の安齋將志氏だ。
PayPay銀行のデータ活用基盤は、マーケティング用の顧客情報データベースの取り引き情報などを集約するデータベースを、「情報系データベース」としてオンプレミスで構築し運用している。この情報系データベースは、SolarisベースのサーバーにOracle Databaseの2ノードRAC構成、インメモリデータベース機能も活用し運用されている。しかしながら最近は、業務量、顧客数の増加に伴うデータ量の肥大化などで性能の劣化が課題だった。そのため、 一部の分析処理をクラウド上の「分析データベース」に分離し負荷の分散が検討されていた。
選定理由 – 実績あるAmazon Redshiftと使い勝手が良いQlik Replicateを採用
これらの条件を満たす環境として、分析データベースのプラットフォームにはAWSの「Amazon Redshift」が選ばれた。また情報系データベースからAmazon Redshiftにデータを同期する仕組みとしては、データインテグレーションツールとして「Qlik Replicate」が採用された。さらに、データマスキングツールとしては、「Insight Data Masking」が選ばれた。
PayPay銀行では既にAWSのサービスを使っていたこともあり、Amazon Redshiftであればそれらと連携が容易で、開発や機能拡張が迅速にできると判断された。その上で、国内での実績が多く、価格も手頃だったことがRedshiftの採用ポイントとなっている。
Qlik Replicateについては、使い勝手が良く設定も容易で価格が安価な点が評価された。PayPay銀行ではこれまで他のデータレプリケーションツールも利用していたが…"
松尾芭蕉(https://ja.wikipedia.org/wiki/%E6%9D%BE%E5%B0%BE%E8%8A%AD%E8%95%89),"松尾 芭蕉(まつお ばしょう、寛永21年(正保元年)(1644年) - 元禄7年10月12日(1694年11月28日)[1][2])は、江戸時代前期の俳諧師。伊賀国阿拝郡(現在の三重県伊賀市)出身。幼名は金作[3]。通称は甚七郎、甚四郎[3]。名は忠右衛門、のち宗房(むねふさ)[4]。俳号としては初め宗房(そうぼう)[2]を称し、次いで桃青(とうせい)、芭蕉(はせを)と改めた。北村季吟門下。
芭蕉は、和歌の余興の言捨ての滑稽から始まり、滑稽や諧謔を主としていた俳諧[5]を、蕉風と呼ばれる芸術性の極めて高い句風[6]として確立し、後世では俳聖[7]として世界的にも知られる、日本史上最高の俳諧師の一人である。但し芭蕉自身は発句(俳句)より俳諧(連句)を好んだ[8]。
元禄2年3月27日(1689年5月16日)に弟子の河合曾良を伴い江戸を発ち、東北から北陸を経て美濃国の大垣までを巡った旅を記した紀行文『おくのほそ道』が特に有名である。"対象データの登録
最初にこのファイルをIDM Managerへアップロードします。
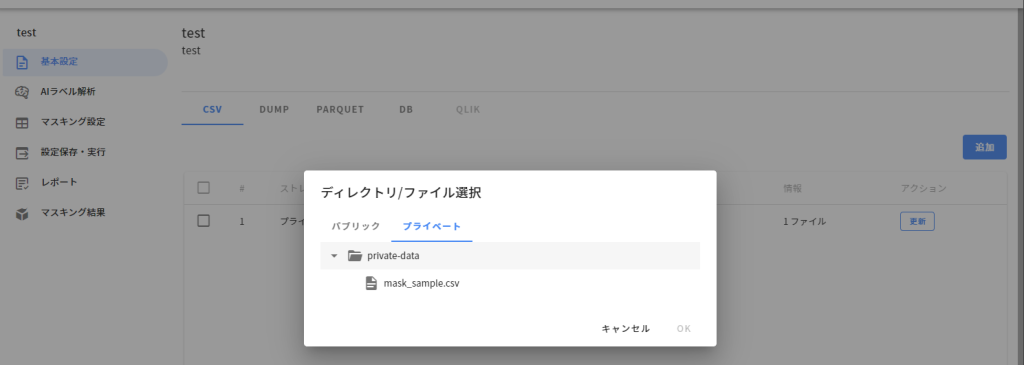
アップロードしたCSVファイルに対してマスキングの設定を行います。
マスキングの実行前の確認
今回はフリーテキストマスキングを行う文章のカラムに対して、「フリーテキストマスキング」の設定を行います。
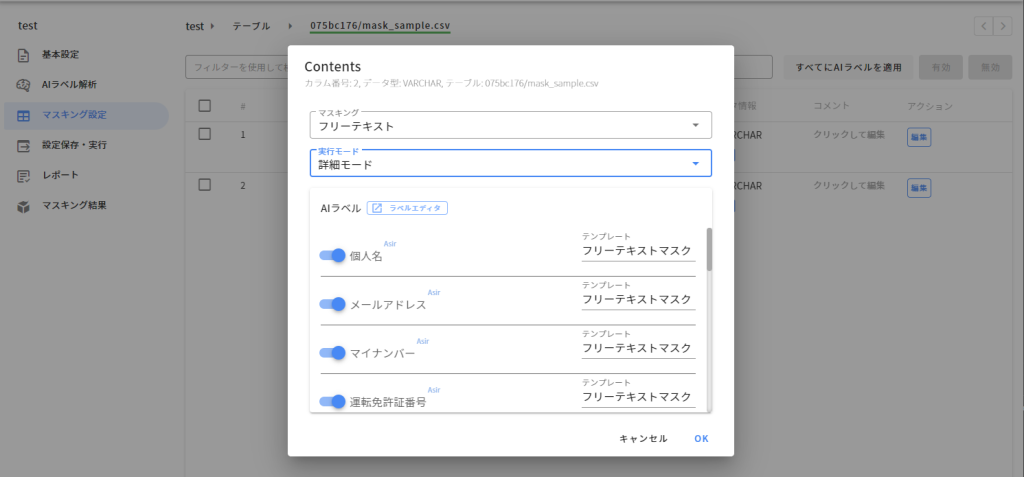
文章から個人情報を抽出するといっても、実際、どのような形で抽出されるのか、事前に確認されたいのは当然だと思います。Insight Data Maskingでは、実際、どのように個人情報が抽出されるのか、GUI上で確認することができます。「ラベルエディタ」をクリックしてみましょう。
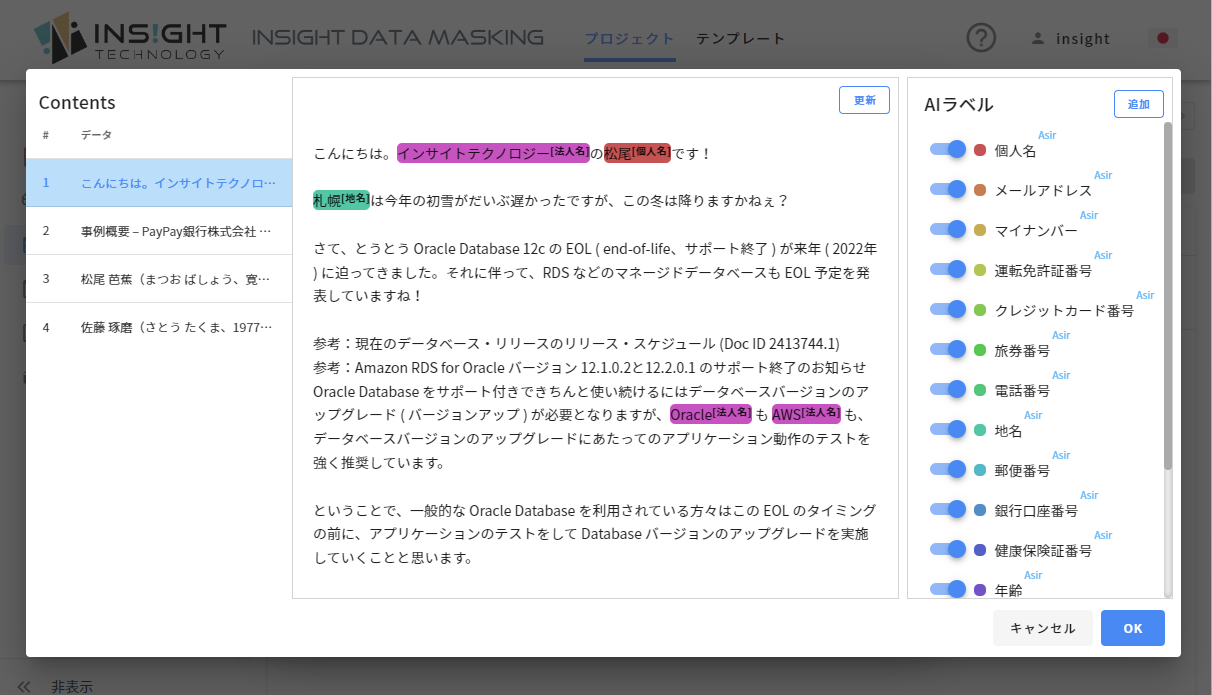

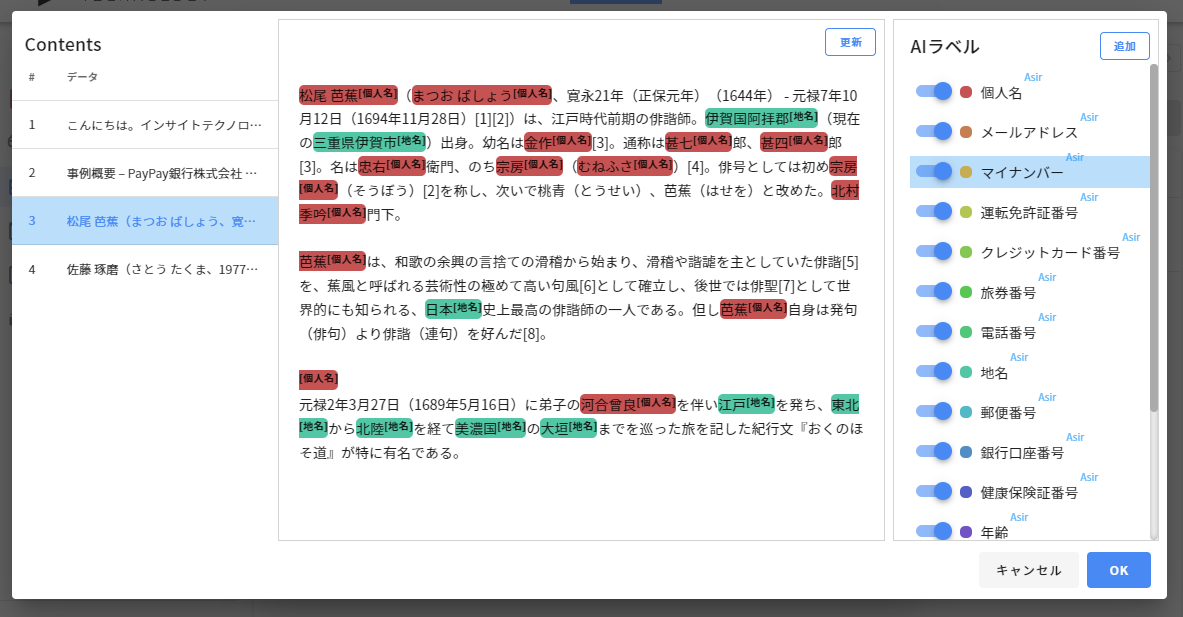
私が以前投稿したブログでも、私の名前や会社名、地名がマスクされていることがわかると思います。同じ「Oracle」という単語でも、製品名の一部になっているものはマスキングされていないのは興味深いですね。Insight Data Maskingでは単純な単語の正規表現によるマッチングではなく、Deep Learningで事前に文章を学習させたうえで、その単語が何に分類されているかを判別しています。
マスキングの実行
マスキングが想定通りに実行できそうであれば、あとは実行するだけです。
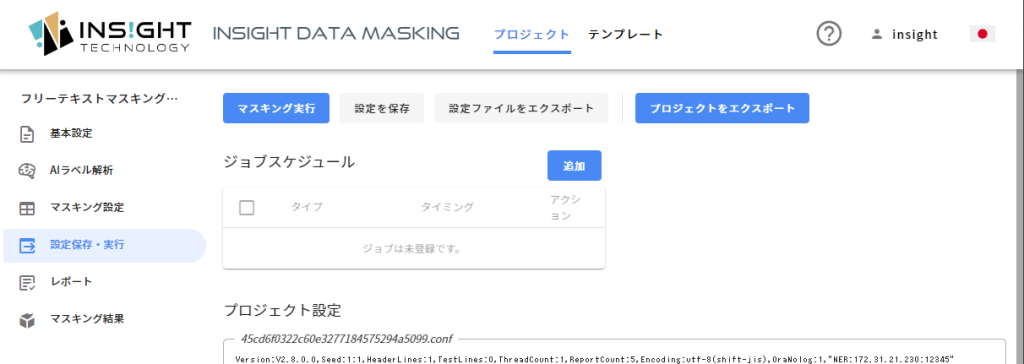
マスキング結果の取得
マスキング結果を確認してみましょう。事前に指定された箇所がマスキングされていますね。今回は設定画面で確認もしていますので、設定画面で確認した通りにマスキングされていることがわかると思います。
マスキング対象の追加やマスク方法の修正
ところで、もともとは個人情報とは関係ない(とシステム上みなされた)単語についても、ユースケースによってはマスキングしたいケースはあると思います。Insight Data Maskingでは、ユーザーが単語登録することで、マスキング対象を追加することができます。
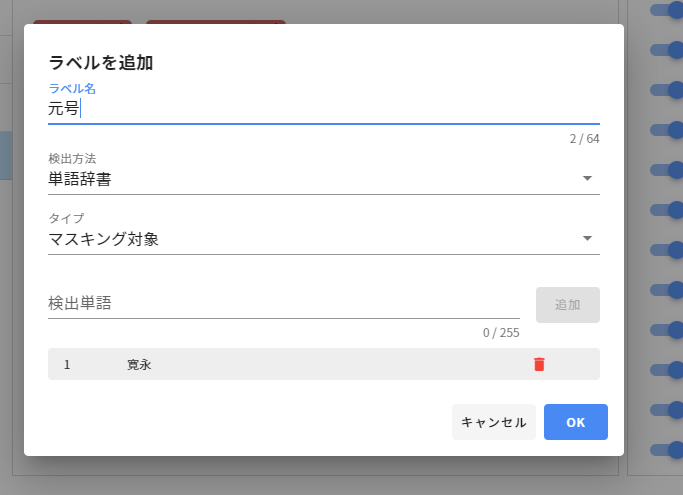
ここでは「元号」を追加してみました。松尾芭蕉のくだりが、元号についてもマスキング対象となっていることが確認できるでしょうか?
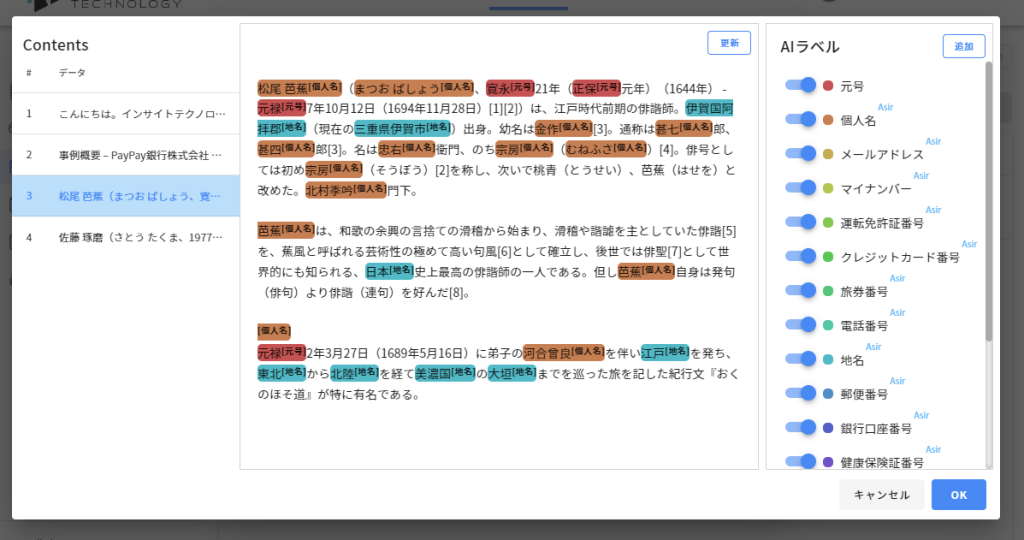
なお、マスキングされ方については、単純な「*」などによる伏字以外にも、いろいろなマスキング方法が選べます。例えば、元のデータが、個人名だったか会社名だったかをわかるようにマスキングしたいケースもあると思います。ここでは、個人名について「[**個人名削除**]」、会社名について「[**会社名削除**]」となるようにマスキング設定を変更してマスキングした結果を貼っておきます。
Name,Contents
松尾拓真(https://www.insight-tec.com/tech-blog/idt/20211223_idt_oracle/),"こんにちは。[**会社名削除**]の[**個人名削除**]です!
**は今年の初雪がだいぶ遅かったですが、この冬は降りますかねぇ?
さて、とうとう Oracle Database 12c の EOL ( end-of-life、サポート終了 ) が来年 ( 2022年 ) に迫ってきました。それに伴って、RDS などのマネージドデータベースも EOL 予定を発表していますね!
参考:現在のデータベース・リリースのリリース・スケジュール (Doc ID 2413744.1)
参考:Amazon RDS for Oracle バージョン 12.1.0.2と12.2.0.1 のサポート終了のお知らせ
Oracle Database をサポート付きできちんと使い続けるにはデータベースバージョンのアップグレード ( バージョンアップ ) が必要となりますが、[**会社名削除**] も [**会社名削除**] も、データベースバージョンのアップグレードにあたってのアプリケーション動作のテストを強く推奨しています。
ということで、一般的な Oracle Database を利用されている方々はこの EOL のタイミングの前に、アプリケーションのテストをして Database バージョンのアップグレードを実施していくことと思います。"
Paypay銀行事例(https://www.insight-tec.com/resource/qlik-replicate/paypaybank/),"事例概要 – [**会社名削除**]
[**会社名削除**]では既存の情報系データベースの処理性能不足問題を解決するため、クラウド上に分析データベースを構築し負荷を分散することを考えた。新たな分析データベースのために選んだのが、Amazon RedshiftとデータインテグレーションツールのQlik Replicateだった。
さらにデータマスキングツールのInsight Data Maskingも併せて採用される。これらを組み合わせた分析データベースでは、データ同期が自動化され、個人情報のデータをマスキングしても柔軟な分析が迅速に行える環境が完成した。
導入背景 – 性能劣化の課題解決のためクラウド上に新たな分析データベースの構築を検討
2000年10月に**初のインターネット専業銀行として誕生した[**会社名削除**]。2021年4月には[**会社名削除**]に改称され、[**会社名削除**]の各サービスとの連携を強化している。
[**会社名削除**]の口座数は約550万、預金残高はおよそ1.3兆円、ピーク時には1時間当たり67万あまりの取り引きが行われ、ユーザーの3割がPC、7割がスマートフォンでサービスを利用している。[**会社名削除**]はもちろん、freeeやMoney Forward、[**会社名削除**]や[**会社名削除**]など多くの提携先があり、PayPayやLINE Pay、メルペイなどさまざまなスマホ決済とも連携している。また顧客サポートではLINEを使ったAIチャットなども実現し、さまざまな面から顧客満足度向上に取り組んでいる。[**会社名削除**]
多くのサービスと連携しより良いサービスを提供するには、データ活用が欠かせない。そのため「社内においては、データ活用のためのデータ分析基盤が極めて重要となっています」と言うのは、[**会社名削除**] IT本部 ***部 基盤開発第一グループ の[**個人名削除**]氏だ。
[**会社名削除**]のデータ活用基盤は、マーケティング用の顧客情報データベースの取り引き情報などを集約するデータベースを、「情報系データベース」としてオンプレミスで構築し運用している。この情報系データベースは、SolarisベースのサーバーにOracle Databaseの2ノードRAC構成、インメモリデータベース機能も活用し運用されている。しかしながら最近は、業務量、顧客数の増加に伴うデータ量の肥大化などで性能の劣化が課題だった。そのため、 一部の分析処理をクラウド上の「分析データベース」に分離し負荷の分散が検討されていた。
選定理由 – 実績あるAmazon Redshiftと使い勝手が良いQlik Replicateを採用
これらの条件を満たす環境として、分析データベースのプラットフォームには[**会社名削除**]の「Amazon Redshift」が選ばれた。また情報系データベースからAmazon Redshiftにデータを同期する仕組みとしては、データインテグレーションツールとして「Qlik Replicate」が採用された。さらに、データマスキングツールとしては、「Insight Data Masking」が選ばれた。
[**会社名削除**]では既に[**会社名削除**]のサービスを使っていたこともあり、Amazon Redshiftであればそれらと連携が容易で、開発や機能拡張が迅速にできると判断された。その上で、国内での実績が多く、価格も手頃だったことがRedshiftの採用ポイントとなっている。
Qlik Replicateについては、使い勝手が良く設定も容易で価格が安価な点が評価された。[**会社名削除**]ではこれまで他のデータレプリケーションツールも利用していたが…"
松尾芭蕉(https://ja.wikipedia.org/wiki/%E6%9D%BE%E5%B0%BE%E8%8A%AD%E8%95%89),"[**個人名削除**]([**個人名削除**]、**21年(**元年)(1644年) - **7年10月12日(1694年11月28日)[1][2])は、江戸時代前期の俳諧師。******(現在の******)出身。幼名は[**個人名削除**][3]。通称は[**個人名削除**]郎、[**個人名削除**]郎[3]。名は[**個人名削除**]衛門、のち[**個人名削除**]([**個人名削除**])[4]。俳号としては初め[**個人名削除**](そうぼう)[2]を称し、次いで桃青(とうせい)、芭蕉(はせを)と改めた。[**個人名削除**]門下。
[**個人名削除**]は、和歌の余興の言捨ての滑稽から始まり、滑稽や諧謔を主としていた俳諧[5]を、蕉風と呼ばれる芸術性の極めて高い句風[6]として確立し、後世では俳聖[7]として世界的にも知られる、**史上最高の俳諧師の一人である。但し[**個人名削除**]自身は発句(俳句)より俳諧(連句)を好んだ[8]。[**個人名削除**]
**2年3月27日(1689年5月16日)に弟子の[**個人名削除**]を伴い**を発ち、**から**を経て***の**までを巡った旅を記した紀行文『おくのほそ道』が特に有名である。"おわりに
本ブログでは、Insight Data Maskingにおける、文章の中の個人情報を自動的に検出してマスキングする「フリーテキストマスキング」機能について紹介しました。
マスキング対象が大量にある場合に、全てについてこのように確認しながら実施できるかは運用次第になるとは思います。また、製品をご紹介した際に必ず尋ねられる「個人情報の全て(100%)をマスキングしていると保証できるのか」という問いについてですが、完全性を保証することはできません。これは、人が作業しても保証することができないのと同じだと思います。繰り返しになりますが、現在「人力で」作業をされている場合でも、最初の作業者のマスキング作業後にダブルチェック、トリプルチェックとおそらく行っていると思いますが、それでも100%にはなりません。最初の作業の大幅な省力化/時短化としても十分検討に値すると考えています。
いずれにしても、ご自身のデータでどのような形でマスキングされるかをご確認いただくことが重要だと思います。このInsight Data Maskingの「フリーテキストマスキング」機能について、製品の詳細な説明やデモ、トライアルなどをご希望される場合は Insight Data Maskingに関するお問い合わせ よりお問い合わせいただければと思います。
次回もどうぞお楽しみに!


